Benchmarking Nine Compression Algorithms on Real-World Data.
Apr 2026
As part of my research into memory systems, I wanted to get a feel for how different compression algorithms actually behave for different workloads. This culminated in a small project focused on implementing 9 compression algorithms in C++, instead of just reading the papers. The key parameters measured are compression ratio & throughput.
Workloads
Picking the right data sources matters immensely for a compression benchmark. The wrong type of data can either make everything look incredible (highly synthetic), or tell us nothing useful (too narrow).
AI Tensor
There are two tensor workloads. They are sourced from a forward pass through MobileNetV2 with a batch of 16 random 224x224 images, hooks on all ReLU6 layers, captured with PyTorch. MobileNetV2 specifically because it represents a realistic edge model, with depthwise separable convolutions, designed for phones and embedded boards and ReLU6 produces sharper, more exactly zero activation patterns than a standard ResNet.
Primary Workload: int8 activations
Activations quantised to int8 (values in [0, 127] via per-tensor max
scaling), packed eight values per uint64 word. There are
two structural properties that make this data compressible:
- Bounded Range: int8 values sit in [0, 127], so bit 7 (sign bit) is always zero. As a result, at least one bit plane is structurally all-zero even before we touch the data.
- ReLU Sparsity: ReLU clamps all negative pre-activations to exactly zero. As a result, ~65% of values are exactly zero, making the data highly compressible.
Secondary Workload: float32 (for comparison)
These are the same activations before quantisation, as raw IEEE754 float32. These are included to isolate the effect of quantisation on compressibility. The mantissa bits in this format are quasi-random, and most structured algorithms fall apart on this.
Photo
A image of the new BMW M3 Touring GT3 (in JPG, converted to raw RGB bytes, padded to 8-byte alignment). Pixel values have smooth spatial gradients, mild inter-channel correlation, and some runs of near-identical colour in flat regions, but no structural zeroes and no narrow value range.
Sensor Stream
Real atmospheric sensor readings from the UCI Air Quality Dataset. It consists of CO, NOₓ, benzene, humidity from a field deployed sensor array in an Italian city. They are stored as fixed-point int32 values.
Sensor streams perform well with delta encoding, as values change slowly and predictably. This workload shows which algorithms exploit temporal correlation and which rely purely on value-level sparsity. It also provides a benchmark rooted in a realistic use case: IoT telemetry.
Random
A Mersenne Twister (mt19937_64) stream, uniform over all
64-bit values. There is no structure, no correlation, flat entropy. It
provides the baseline for incompressible data. Most likely any algorithm
that actually provides a compression ratio greater than 1 is doing
something wrong.
Algorithms
Zero Value Compression
This is the simplest algorithm, in a nutshell, we write a bitmap of which words are non-zero, then the non-zero values. For sparse data, this ends up being quite competitive, and since the decompression path is a single bitmap scan, it reaches very high throughput.
Delta Encoding
This algorithm involves storing the first word as is, and then storing differences between consecutive words in place of the word itself. This is great when values change slowly/predictably. It ends up being poor for random data as the difference is just as unpredictable as the original values.
BDI - Base Delta Immediate
This algorithm processes 64-byte blocks (8 * uint64) by
finding a base value, checking whether all deltas fit in
int16, and storing base + 8 *
int16 deltas instead of eight full uint64
values if so. This results in three paths per block: all-zero (with tag
0x00), BDI (with tag 0x01), and raw fallback
(tag 0x02).
FPC - Frequent Pattern Compression
This algorithm assigns a 3-bit tag per word, each representing 1 of 8 possible patterns, which are zero, sign-extended 4-bit, sign-extended byte, sign-extended int16, halfword repeated 4 times, byte repeated, sign-extended int32 or no match (resulting in uncompressed data). Two tags are packed per byte and matched words are stored at their compressed width, and unmatched words raw.
LZ4-Style Block Compression
This algorithm involves greedy byte-sequencing matching with a 64K
hash table. It encodes back-references as (offset, length)
pairs interleaved with literal runs. The last 5 bytes of any block are
always stored as literals.
Snappy-Style Block Compression
This is very similar to LZ4, except with a 4K hash table and the match length is capped. It provides a slightly lower ratio but the smaller table fits comfortably on the L1 cache of small cores, providing a big performance boost.
Zero + BDI Cascade
This is a two level scheme, where it cheks for all-zeroes first, then
tries BDI, then falls back to raw data if all else fails. It is designed
to combine the strengths of both, and in practice it runs into some
trouble with packed int8 data because BDI's delta check operates at the
uint64 level, not the byte level and the eight packed byte
don't produce narrow word-to-word deltas.
BPC - Bit Plane Compression (Simplified)
This is a simplified version of the Bit Plane Compression algorithm. It operates on 64-word blocks to form a 64*64 bit matrix. It then transposes the matrix so each row is a one bit-plane, then writes a 64-bit zero-plane mask, then stores only the non-zero planes. The key factor here is that if most words are zero, most bit-planes will be all (or nearly all) zero. These zero planes cost only 1 bit in the mask.
BPC-Spec - Bit Plane Compression
This actually meets the spec of BPC as per the original paper (J. Kim, M. Sullivan, E. Choukse, and M. Erez, ‘Bit-plane compression: transforming data for better compression in many-core architectures’, SIGARCH Comput. Archit. News, 2016). The key difference compared to the simplified version that was also implemented is that it wraps the bit-plane transpose with two additional stages: delta before the bit-plane stage & XOR after the bit-plane stage.
Delta
Correlated consecutive values yield small deltas, concentrating non-zero bits into lower planes.
XOR
Since adjacent bit-planes after delta are often identical, XOR encodes only the change between the deltas.
Finally, partial blocks are padded with the last value (non-zero), so that the padded deltas are zero and don't corrupt the planes.
Result
The result achieved can be seen in the following image:
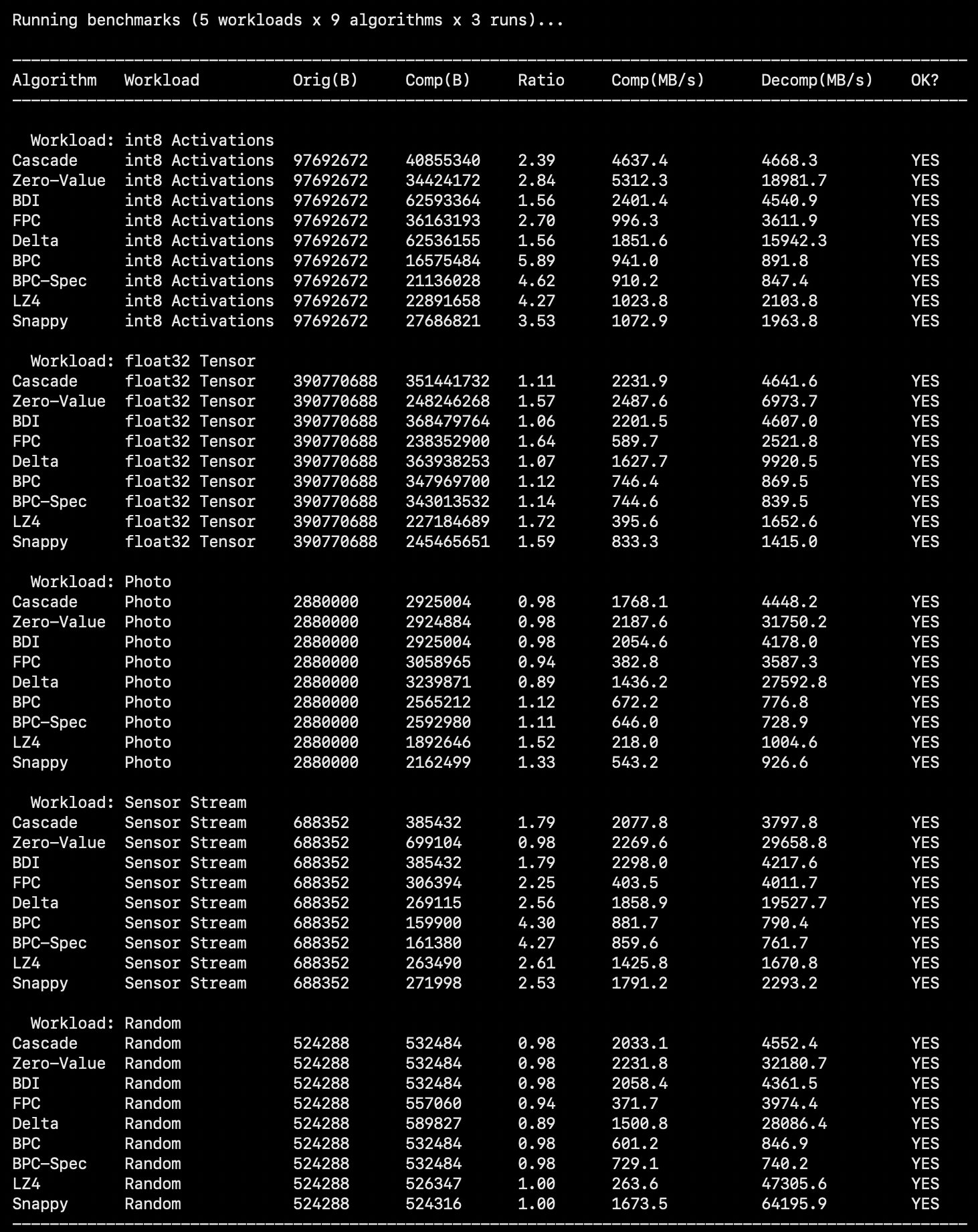
Note that the throughput figures are software measurements on my mac, and that they reflect relative algorithm complexity & not real hardware latency. Additionally, the LZ4/Snappy decompression at ~50 GB/s on random data is an artefact of the branch predictor recognising incompressible structure and short-circuiting almost all decode work.
Analysis
int8 Activations
Simplified BPC yields the best compression ratio here (5.89), and the ratio is also analytically predictable. This data has about ~65% zero bytes, a bounded range [0, 127] and the bit 7 plane is structurally all-zeroes. Additionally, most of the remaining planes are also near-zero due to block-level sparsity. This leaves roughly 10 non-zero planes per block, giving us 512 / (8 + 10 * 8) = ~5.8%. The measurement matches the theoretical value.
At a compression ratio of 4.27, LZ4 is a great option as a general purpose codec.
Zero-Value at 2.84 is also a great option along due to the speed and simplicity of it.
BPC-Spec represents BPC as per its original spec, and it is meaningfully worse than simplified BPC on this workload (4.62 vs 5.89), this is due to the fact that the delta step in BPC relies on consecutive words being correlated, which isn't the case here.
float32
None of the compression algorithms fare particularly well here, but LZ4 leads at a compression ratio of 1.72. Floating point mantissa are quasi-random, breaking bit-plane and pattern-matching approaches. FPC fares reasonably well by detecting the zero pattern for exact-zero floats and catching near-zero values in its narrow-range classes.
Photo
Photo data sits at an awkward middle ground, not random enough to be incompressible, but not structured enough for the specialised algorithms. LZ-4 & Snappy lead (at compression ratios of 1.52 & 1.33 respectively) as byte-level repetition in smooth regions of the image and the limited byte-value range of the image benefit them greatly.
BPC & BPC spec both provide a very marginal gain, both because natural images aren't uniformly distributed.
The rest of them end up expanding the image, which isn't ideal.
Image data requires a codec that understands the spatial structure of the image, and since none of the algorithms here do that, we get mediocre results by treating raw pixels as a generic byte stream.
Random
Random data is incompressible by all algorithms and yields a compression ratio of <= 1 from all of them. Diving deeper, Delta provides the worst ratio, because the differences of the random values have twice the entropy of the original values. FPC expands due to the tag byte overhead when no patterns match.
Conclusion
Compression effectiveness is extremely workload-dependent.
Bit-plane compression performs extremely well on sparse, bounded range data as seen, but no benefit when the structure is absent.
Delta-based schemes depend on inter-word correlation, and their performance hinges solely on this.
LZ4 and Snappy, being general purpose codecs, provide the best overall performance when it comes to compression ratio across workflows, but their complexity limits them to being software only, being too complex to implement efficiently in hardware.
Incompressible data results in expansion or breaking even as a best case, reinforcing the entropy-bound nature of compression.
The code for this project can be found at: Compression Algorithms